From War Rooms to Mission Control: How AI SRE Is Reimagining Production Operations

AI SRE, or AI agents for site reliability engineering, is changing how enterprises operate production systems at scale. Not by adding new tools on top of existing workflows, but by reimagining the operating model itself: who does what, when, and with what information.
To understand why that reimagining is necessary, it helps to start with what the current model actually looks like under pressure and where it consistently breaks down.
To see Traversal’s AI SRE, the first to be validated within the Fortune 100, book a demo today.
The Operating Model Most Enterprises Are Still Running
Here's what typically happens during an incident:
- An alert fires. An on-call engineer opens their laptop.
- They pull up dashboards, scan for obvious signals, and check recent deployments.
- Nothing obvious. They post in Slack asking if anyone else saw something change.
- Twenty minutes in, they escalate to the service owner.
- The service owner investigates their slice and finds nothing wrong.
- They escalate again. Now it's 11pm and three teams are on a bridge.
- Over an hour in, someone traces the failure four hops away from where the symptom surfaced.
This is not an unusual incident.
Most enterprise on-call structures follow a tiered escalation model. L1 is the first line: a NOC (network operations center) or mission control team, often non-technical, watching alerts across the environment, often 24/7. L2 is the service or domain owner who gets paged when L1 can't remediate it alone. L3 is the senior engineer or architect with the deep system expertise: the permanent escalation target for everything the earlier tiers can't close. The walkthrough above is what it looks like when an incident has to traverse all three.
The reason it plays out this way isn't incompetence or bad tooling. It's that the operating model was built around a core assumption that no longer holds: that a skilled engineer, with the right dashboards and enough domain knowledge, can still form a usable model of what a complex distributed system is doing, fast enough to matter.
In the systems most enterprises are running today, that assumption is broken.
What Changed Underneath the Operating Model
Three things happened simultaneously, and their interaction is what makes the current operating model structurally inadequate, not just difficult.
- Systems became more complex. A single customer request now routinely touches dozens of services before it completes: application logic, queues, caches, identity systems, feature flags, third-party APIs, model endpoints. Each owned by a different team. Each with its own telemetry vocabulary. When something goes wrong, the symptom surfaces in one place and the cause lives somewhere else entirely. No single engineer holds the full picture, and the path from symptom to root cause crosses boundaries that no runbook was written to traverse.
- Change got faster. AI-assisted development has increased the volume of code shipping per engineer by roughly 55%. The system map from last quarter may be directionally correct but operationally wrong today: new services added, dependencies changed, ownership shifted. When an incident happens, responders are navigating a city that's been substantially rebuilt since the map was drawn.
- The failure surface got stranger. AI-enabled components fail differently than deterministic code. A service can return a 200 on time while producing output that's wrong, stale, or unsafe. Standard monitoring has no signal for this. The dashboard looks green. The system is failing. The gap between surface health and user-visible correctness is invisible to every tool in the current stack.
Put these three together and you get the defining operational problem of the AI era: the system has outgrown the operator. This is not because engineers aren't skilled. Because the environment has structurally exceeded what human-centered investigation workflows were built to handle.
What the Broken Operating Model Actually Costs
The visible cost is MTTR. The less visible cost is everything that happens during the investigation.
When an engineer anchors on the wrong hypothesis (the deployment that went out an hour before the incident, the service that always seems to be involved) the correct investigation doesn't start until the wrong one ends. A wrong rollback doesn't just fail to fix the incident. It can introduce new instability. Paging the wrong team burns their attention and creates organizational noise. Forty minutes spent on a false lead means forty minutes of real user impact that didn't have to happen.
These costs don't show up in availability metrics. They show up in MTTR calculations that never seem to improve despite continued investment in observability.
The problem isn't visibility. Organizations have spent two decades and billions of dollars closing the visibility gap, and they've largely closed it. The problem is reasoning. Converting the telemetry that already exists into a correct, causally validated explanation of what's happening, fast enough to act on it: that's the bottleneck.
What AI SRE Changes
AI SRE addresses the reasoning bottleneck directly. Not by adding more dashboards or more alerts, but by changing what happens in the minutes after an alert fires.
In the current model, the first fifteen minutes of a serious incident are spent assembling context: What's the blast radius? Which deployments are candidates? Which services are affected? Which team should be paged? An experienced engineer runs this loop competently, but it's slow, sequential, and bounded by working memory and available attention.
In the AI SRE model, most of that context arrives before the engineer opens their laptop.
The system has already traversed the dependency graph from the symptom location. It has evaluated hundreds of hypotheses in parallel, not sequentially, and has surfaced a ranked list of candidates with supporting evidence chains. That shift, from assembling context to evaluating causally validated root cause, is where most of the time savings come from. But it's also where most of the quality improvement comes from. Anchoring on the wrong explanation early is the single most expensive thing that happens in a modern incident. Starting with a structured, evidence-ranked hypothesis set instead of a blank slate dramatically reduces the probability of that happening.
The Changed Workflow, Role by Role
- The on-call engineer stops being the first person to assemble the picture from scratch and becomes the first person to evaluate one. Alert fires → read structured summary with blast radius, ranked hypotheses, supporting evidence, similar prior incidents → validate and act. Five to ten minutes saved per incident. More importantly: far less likely to anchor on the wrong explanation at minute two.
- The incident commander opens the bridge to find a structured incident state already populated. Confirmed impact. Dependency path. Ranked hypothesis list with weakened alternatives. Their job from minute one is direction and decision-making — not information gathering. They assign investigation threads from a structured starting point. They make the escalation call with a causal model already in hand.
- The L3 expert stops being the permanent escalation target for every multi-hop incident that stumped L1 and L2. With AI doing the cross-boundary causal reasoning, the volume of incidents that actually require L3 judgment, such as genuinely novel failure modes, and high-stakes remediation decisions, drops significantly. The ones that do reach L3 are the ones that actually need them.
- The SRE lead gains visibility into investigation quality, not just incident frequency and duration. Which services generate the most complex investigations? Which dependency patterns cause repeated confusion? Which alert designs consistently produce bad first hypotheses? That data enables a different kind of reliability work: not just responding to incidents, but systematically reducing the cognitive cost of the ones that do occur.
The Current Escalation Model Has to Change
The current escalation model triggers movement between tiers when a team runs out of expertise. L1 escalates because the runbook doesn't cover it. L2 escalates because the root cause appears to sit in a service they don't own. L3 gets paged for everything that fell through.
This made sense in an environment where expertise was the binding constraint. It does not make sense in one where the binding constraint is reasoning across systems that no individual fully holds. Under the current model, an L1 operator who can see that an alert involves a service they don't own has effectively one option: escalate. Not because they couldn't act, but because they have no way to form a defensible view of what's happening. Escalation is the only path to a hypothesis.
The result is structural over-escalation. Senior engineers get paged for incidents that don't actually require their expertise, only their willingness to do the cross-boundary reasoning that nobody else has the tools to do. L2 and L3 spend a disproportionate amount of their time being the connective tissue between tiers, not the deep experts they were promoted to be. The cost shows up everywhere: senior engineer burnout, slower MTTR, an on-call rotation that gets harder to staff every year, and an L3 bench that's increasingly the only thing standing between the business and a bad night.
AI SRE changes the trigger. Escalation happens when a team runs out of authority, not knowledge. The L1 operator now has the same causal picture an L3 would have built manually, which means they can form a real view of what's happening. What they may not have is the permission to restart the database, roll back the deploy, or take the customer-facing action the diagnosis points to. That's when the incident moves up: not when the thinking runs out, but when the mandate does.
The reasoning that previously lived only at L3 (full dependency graph traversal, cross-boundary causal tracing, pattern matching against prior incidents) becomes available at L1. The mission control operator doesn't need to understand every service they're watching. They need to evaluate an AI-generated diagnosis, validate it against what they can observe, and either act within their authority or escalate with a structured causal summary rather than "this alert fired and I don't know why."
This is a meaningful change in what each tier is for. L1 stops being a routing layer and becomes a decision layer: the first place where a real diagnosis can be evaluated and, in many cases, remediated. L2 stops being the default escalation target for anything that crosses a service boundary and starts seeing only the incidents that genuinely require their domain expertise. L3 stops being the perpetual backstop for the operating model and becomes what they were always supposed to be: the people who handle the genuinely novel failure modes and the high-stakes remediation decisions that should require human judgment.
This flattens the frequency of unnecessary escalation without eliminating tiers. L1, L2, and L3 still exist. What changes is how often each level gets involved and why.
The longer-term implication is bigger. When mission control has agentic reasoning available at the first point of contact, the role itself starts to change shape. It stops being a queue of alerts to acknowledge and starts being a command surface where most incidents are diagnosed, scoped, and either remediated or routed with full context, before they ever become escalations. That shift, from mission control as an alert-handling layer to mission control as the operational nerve center of the production environment, is something we call Agentic Mission Control, a subject worth treating on its own. We'll be writing about it separately.
The Deeper Shift: Operational Knowledge Stops Walking Out the Door
The escalation change is structural. The change underneath it is about institutional memory.
Today, the operational knowledge that actually runs a production environment is stored in people. The senior SRE knows that this particular service has a memory leak that surfaces under exactly the load pattern that hits on Black Friday. The platform engineer remembers that this dependency was rewritten two years ago and the old failure modes don't apply anymore. The on-call lead has a working theory about why the queue depth alert is noisy on Tuesdays. None of this is written down. Most of it can't be written down: it's understanding built over years of specific incidents, and the people who hold it usually don't know they hold it until someone asks the right question at 3am.
This creates a quiet but compounding organizational risk. When a senior engineer leaves, years of operational context leave with them. Runbooks capture some of it. Postmortems capture more. But the informal knowledge: the heuristics, the known fragilities, the instinct for which signals to trust largely evaporates. The replacement hire will eventually rebuild a version of it, over years, by being on call for incidents the previous engineer had already solved once.
Every enterprise running a complex production environment is, today, running on operational knowledge it does not own. It rents that knowledge from the engineers who hold it, and pays the rent in retention bonuses, on-call premiums, and the steady acceptance that incident response quality is a function of who's on the bridge.
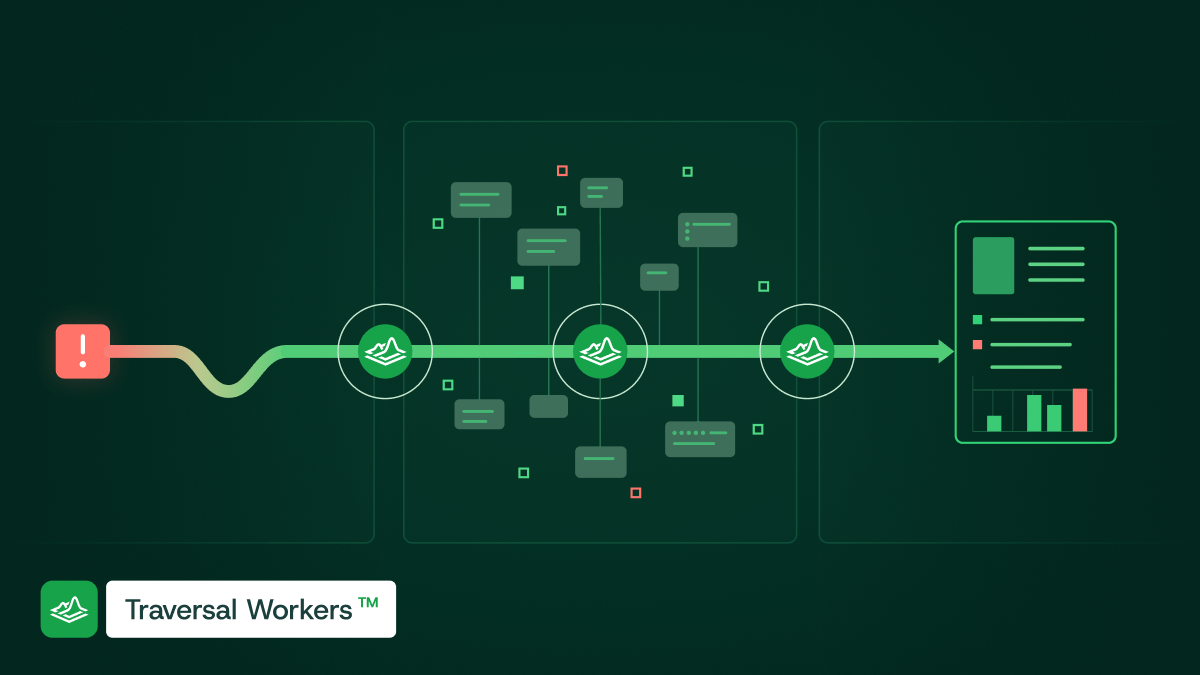
AI SRE changes this. Operational knowledge—the dependency relationships, the historical incident patterns, the signal-to-noise calibration for each service, the failure modes that have surfaced before—gets encoded continuously into the Knowledge Bank™ that's available to everyone. The institutional memory of the production environment stops being distributed across human heads and becomes part of the Production World Model™, an AI-readable model of your entire production environment.
And once an organization runs production this way, the knowledge keeps accumulating: every incident makes the Production World Model™ smarter. The compounding direction reverses. Today, operational knowledge depreciates with every departure. In an AI SRE operating model, it appreciates with every incident.
The quality of incident response should not be a function of which engineer happens to be awake. It should be a function of how good the operating model is. AI SRE is what finally decouples those two things.
The Operating Model Changes in Several Directions at Once
The operating model is shifting in several directions at the same time, and the directions matter together more than any one of them does alone:
- The first fifteen minutes of an incident shifts from context assembly to diagnosis evaluation. The on-call engineer is no longer building a picture from scratch; they're validating one and acting on it.
- The escalation trigger shifts from knowledge to authority. Tiers stop being a queue for whoever can figure it out next and start being a model of organizational accountability.
- The storage layer for operational knowledge shifts from human heads to the production environment itself via Production World Model™ and Knowledge Bank™. Institutional memory stops walking out the door with every senior departure and starts compounding with every incident worked.
- Mission control itself shifts from an alert-handling escalation layer to an agentic one. The picture gets assembled, the diagnosis gets formed, and most incidents get remediated or routed before they ever reach a human bridge, with humans setting direction and handling the decisions that require judgment.
None of these shifts is, on its own, the change. The change is that they happen together, and they reinforce each other. Faster diagnosis flattens escalation. Flatter escalation surfaces patterns that sharpen the model. A sharper model makes the next diagnosis faster. The whole thing compounds.
This is what makes the AI SRE shift different from previous waves of operations tooling. Observability, runbook automation, AIOps: each improved one part of the existing model. AI SRE changes the model itself, in enough places at once that the parts can no longer be considered separately. The organizations that approach this as a tooling decision will get tooling-sized results. The ones that approach it as an operating model decision will get the compounding.
See how Traversal can transform your production operations today by booking a demo.
FAQ
AI SRE, or AI agents for site reliability engineering, applies agentic AI to the investigation, diagnosis, and remediation of production incidents. Traversal’s AI SRE builds a continuously updated, AI-readable model of the production environment and uses causal reasoning to surface root causes. The goal of an AI SRE is not to entirely replace SRE discipline but to apply agentic AI in an environment that has grown beyond what human-centered investigation workflows were built to handle.
Observability tools improve visibility. They tell you what the system is doing. AI SRE addresses the reasoning gap: converting that visibility into explanation. A dashboard can show that latency is elevated. It cannot explain why. AI SRE can surface root cause with causally validated evidence, replacing the manual investigation loop that currently falls to on-call engineers.
AI SRE is most critical for enterprises with complex, distributed infrastructure where downtime carries severe business consequences: financial services, fintech, healthcare, e-commerce, and large-scale SaaS. The clearest signal is an escalation model that has broken down: L3 engineers routinely paged by mission control for incidents that turn out not to require their expertise, or MTTR that doesn't improve despite continued observability investment.
The most direct metrics are MTTR, escalation rate, engineering hours saved, and the proportion of incidents remediated without L3 involvement. Beyond incident metrics, track investigation quality: time spent on wrong hypotheses, incidents where the first hypothesis was incorrect, and rework rate introduced by acting on false diagnoses. It can also be reflected in the burnout rates of SREs and on-call engineers, as well as the number of incidents and the length of downtime.


.png)