Leading Global Crypto Exchange Selects Traversal to Improve Incident Response, Reduce MTTR, and Democratize Engineering Knowledge

At a Glance
A leading global cryptocurrency exchange, one of the largest by quarterly trading volume, operates a self-managed, highly distributed platform: nearly 1,500 services across 7+ observability and incident management tools, and dozens of customer-facing products. Petabytes of logs, metrics, and traces flow through that stack daily, all inside the exchange's own VPC under financial-services-grade controls. With over 1,800 production incidents per year across P0–P4 severities, and the company scaling rapidly under an increasingly demanding regulatory environment, operational resilience has become critical.
The exchange ran a head-to-head evaluation between Traversal and other AI SRE vendors across two use cases: agentic incident response and scaling senior SRE expertise to every engineer and operator. Traversal was selected on four factors: superior root cause accuracy, lower investigation latency, a Bring Your Own Cloud (BYOC) deployment model compatible with the exchange's data residency requirements, and the ability to deliver these results without the extensive manual configuration, markdown files, or constant coaching that competing AI SREs required. Within 7 days of initial deployment, Traversal was performing at production-ready levels: projecting 40%+ MTTR reduction and 75% RCA accuracy across in-scope incidents, measured as the share where Traversal either bullseyed the root cause or substantially narrowed the investigation scope. Beyond RCA, Traversal's Chat with Prod agentic capability answered engineering questions in the exchange's shared platform support channels—work previously fielded by senior SMEs—pointing to a path to reclaim the equivalent of 12 senior FTEs and free the platform's most experienced talent to focus on core engineering.
{{testimonial}}
The Challenge
The exchange's reliability team functions as the company's Mission Control: assessing blast radius and coordinating response. As incident volume grows, that mandate has become harder to execute.
Several key structural factors compounded the operational challenge:
- Scale and Velocity of Incidents in a High-Stakes Domain: Over 1800 production incidents per year across P0–P4 severities, on a platform processing billions of dollars in trading volume under financial-services-grade regulatory oversight, mean any customer-facing degradation results in lost trades, regulatory exposure, and erosion of trust.
- Highly Fragmented, Self-Managed Observability Footprint: To maintain control over sensitive financial data, the exchange self-manages most of its platform inside its own VPC, standardized on a best-of-breed stack including Splunk, Victoria Metrics, and Sentry. Assembling a unified picture across nearly 1500 services required engineers to context-switch between query languages, dashboards, and dependency models. MTTR ran from 30+ minutes on the fastest incidents to 8+ hours on the slowest, with 95% of that time spent locating signals and only 5% deploying a fix. Compounded across 100+ incidents per month, that's over 1,100 engineering hours every month pulled into war rooms instead of platform work.
- Tribal Knowledge Bottlenecked in Shared Platform Channels: The exchange operates roughly a dozen shared platform support channels—observability, GitLab, Kubernetes, and more—where senior SMEs answer questions for over 1,000 engineers. At roughly an FTE per channel across a dozen channels, the exchange was burning ~24,000 senior engineering hours per year on platform Q&A: the equivalent of a full platform team's worth of capacity, concentrated on the engineers the company can least afford to lose to reactive work.
Our Deployment
Given the exchange's regulatory posture, deployment requirements were stringent: no sidecars, no agents, no data leaving the VPC. Most AI SRE vendors are SaaS-first, shipping customer telemetry to vendor-managed infrastructure. Traversal's Bring Your Own Cloud (BYOC) architecture met the requirements out of the box, running inside the customer's environment via read-only access to the existing stack.
Traversal’s AI-Native Compressor™ delivers 1000:1 compression with zero signal loss, so the exchange's full production telemetry becomes tractable to reason over without ever leaving the VPC.
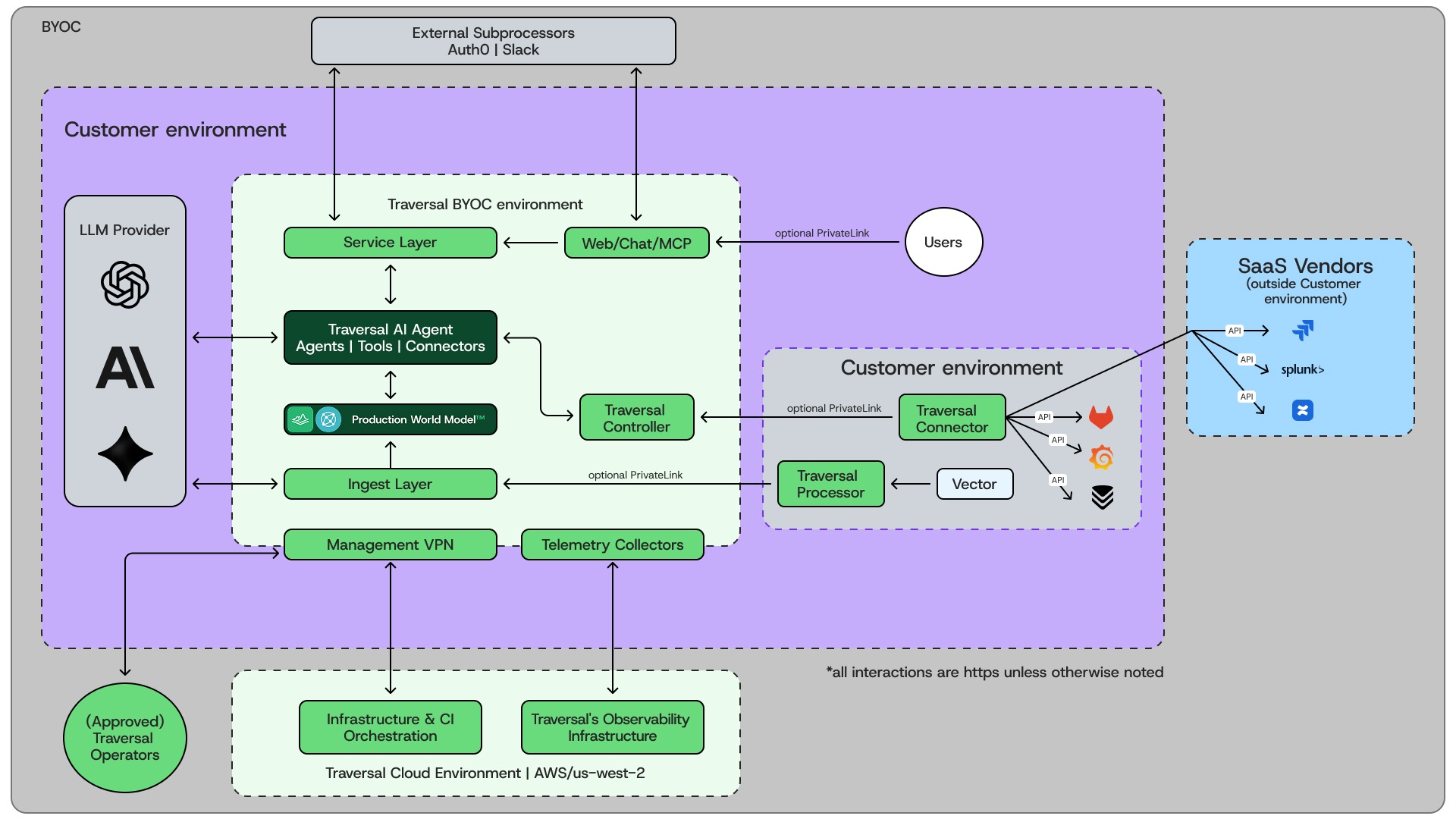
Just as critical as the deployment model was the minimal lift required to get value out of it. The exchange ran a rigorous head to head evaluation and found that competing AI SREs required their engineers to author and maintain large libraries of markdown files describing services, runbooks, and dependencies: ongoing toil that scales with the platform. On the other hand, Traversal’s AI SRE produced actionable RCAs within seven days of deployment with no markdown authoring, no runbook migration, and no standing engineering investment from the exchange.
The evaluation itself was engineer-led and apples-to-apples. Two senior engineers from the exchange ran a four-day backtest against the Traversal product, replaying 25 real production incidents against production-scale data and scoring outputs on accuracy and latency against baseline manual MTTR. Traversal won on all four criteria:
- Higher root cause accuracy
- Lower investigation latency
- BYOC deployment compatible with the exchange's data residency requirements
- Zero manual configuration, markdown authoring, or ongoing coaching by engineers
A separate Chat with Prod evaluation tested the platform-support use case directly: 20 historical investigations were replayed from the exchange's shared support channels and 30 engineering questions were run side-by-side in the UI against the exchange's existing answer baseline, graded for accuracy by the engineers who would be the day-to-day users.
Traversal’s Impact at the Exchange
- Incident RCA for Major Outages: Across the 25 incidents, Traversal delivered an exact root cause analysis—a "bullseye"—on roughly a third of cases, with most remaining cases producing partial diagnoses that significantly narrowed scope or identified the right teams. Aggregated, this translated to a projected 40%+ MTTR reduction as a starting point—an impact expected to grow materially as Traversal autonomously learns the exchange's environment over time.
- Scaling Subject Matter Expert (SME) Capacity via Chat with Prod: Tested against real questions from the exchange's shared platform support channels, Chat with Prod performed strongly even with limited context, pointing to a path to reclaim the bulk of those 24,000 senior engineering hours and return that capacity to platform and reliability work.
At the core of what led to Traversal providing a fundamentally differentiated experience is Traversal’s Production World Model™, which connects the exchange's services, dependencies, code, tribal knowledge, and infrastructure into a unified, AI-readable model, collapsing what would otherwise be dozens of sequential queries across disparate observability platforms into a single multi-threaded investigation. Traversal’s Causal Search Engine™ then causally investigates over it, identifying root cause across the exchange's full stack—from customer-facing trading and order-matching services down through the self-managed VPC infrastructure beneath them. Traversal's Knowledge Bank™ then automatically captures SME institutional knowledge from technical documentation at the company as a last-mile refinement layer on top of what's already been auto-discovered via the telemetry.
Toward Agentic Incident Response in a Regulated, High-Velocity Environment
For a business at the intersection of financial services and crypto, software reliability, and MTTR more specifically, is core to the product. The exchange's evaluation demonstrated that root cause analysis, delivered under strict BYOC and regulatory constraints, can materially reduce MTTR while freeing senior engineers from reactive work, letting the business scale without scaling incident pain in lockstep.
To see how Traversal can work in your environment, book a demo today.
"[A key part of the] decision was because you have the BYOC product—for us, as a security-first company, that's a big plus. And we don't need to maintain extra context on our end. You handle all of that for us: building the Production World Model™, reading the documentation and other sources."


