The Bitter Lesson for Agent Harnesses


Building an agent harness isn't exactly an AI problem, and it isn't a pure software engineering problem either. It's something new. But when your software instincts fight your AI instincts over how to build one, the AI instincts usually win.
In machine learning, the bitter lesson is nearly a cliché. General methods that scale with data and compute beat hand-crafted human knowledge, reliably and by a wide margin — Richard Sutton named the idea in a now-canonical 2019 essay that takes about five minutes to read. Anyone who trains models has long since made peace with it. Many who build agent harnesses act like it does not apply to them — because an agent harness doesn't look like a model. It looks like software.
So we build agent harnesses the way we build software. And there's a failure that follows: the agent dazzles in the demo, falls apart on the hard cases, and the fix everyone reaches for is the same one. Break it into smaller pieces. Put a controller out front. Give each piece one job. It feels like progress. It usually makes the agent worse.
That fix — decompose the problem, bound each part, isolate the failure — is one of the best instincts in all of software engineering. It's just a good instinct for the wrong kind of system. An agent harness is part procedural work, which software does, and part cognitive work, which the model does — a distinction we've drawn before. Your software instincts serve the procedural half well. On the cognitive half they turn against you — and the cognitive half is where the agent actually earns its keep.
Two ways things get better
Software and AI both improve over time. However, they improve in opposite directions.
Software gets better by adding structure. You take a thing that does too much, and you split it. You find a failure mode, and you wall it off. Every iteration, the system has more parts, and each part has a narrower job. Reliability is a product of decomposition: the more precisely each component's responsibility is bounded, the smaller the blast radius when any one of them is wrong. Decades of good engineering practice — modularity, single responsibility, separation of concerns — all point the same way. Add the right boundaries.
AI gets better by removing structure. The history of machine learning is a graveyard of clever, human-designed components that got deleted and replaced by something more general that learned the same thing from data. This is the bitter lesson at its source — Sutton's claim, drawn from seventy years of AI research:
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
The examples all rhyme. Chess fell to Deep Blue's brute-force search, not encoded grandmaster heuristics. Go fell to AlphaGo's search and self-play, not hand-built positional knowledge. Speech recognition and computer vision both threw out hand-crafted features for methods that learned their own. Every time, the people who built their understanding of the problem into the system lost to a more general method handed compute and data and left to figure it out.
The human knowledge you painstakingly encoded wasn't just unnecessary — it was the ceiling. Sutton's conclusion:
We want AI agents that can discover like we can, not which contain what we have discovered.
So: software improves by building in more of what you know. AI improves by building in less of it. An agent harness is made of both — neither purely software nor purely AI — which is exactly why it's so easy to grab the wrong rulebook. The bitter lesson is what tells you which one wins. For a model, it meant don't hand-code knowledge into the learner. For an agent harness, it means don't hand-code your judgment into the software around the model — and the rest of this is what that looks like in practice.
How a software system grows up
Let me make the software instinct concrete, because it really is a good instinct.
Imagine the system-design version of a simple alert pipeline: something pages the right engineer when a service breaks. Day one, it's one box.

It works. Then it doesn't. A traffic spike arrives and the single process can't keep up, so alerts get dropped. You know this move: put a queue in, decouple ingestion from processing.

Now the severity logic grows hairy and starts throwing on edge cases, taking the whole worker down with it. You pull it into its own service with its own tests, so a bug there can't kill paging. And duplicate alerts are paging people twice, so you add a dedup stage.

Look at the trajectory. Every iteration, more boxes, each one smaller and more single-purpose. The classifier can't take down paging. A poison message lands in the dead-letter queue instead of wedging the worker. You can test, deploy, and reason about each box alone. This is software getting better, and it's getting better by exactly the means the discipline prescribes: decompose, bound, isolate.
Now watch what happens when you bring that same trajectory to an agent harness.
The same instinct, applied to an agent harness
You're building an agent harness that investigates production incidents. It works on easy cases and flails on hard ones. Software brain engages. Decompose.
So you draw the obvious architecture:
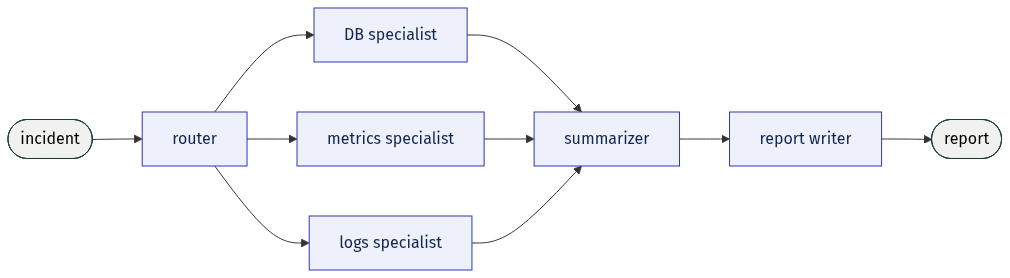
Clean. Single-responsibility components, a clear flow, isolated failure modes. Every box has one job. And nearly every box is a mistake.
The router is a mistake. A router is you, at design time, writing down your taxonomy of what incidents look like and which specialist each one needs. But the entire value of the agent is handling the incident you didn't anticipate. The moment a problem arrives that doesn't fit your routes — a database issue that only shows up as a metrics anomaly that's actually a bad deploy — your router sends it down the wrong path before the intelligence ever gets a vote. You've taken your weakest asset, your advance guess about the problem, and made it the load-bearing first decision. You encoded what you know. Bitter lesson.
The separate summarizer is a mistake. You added it to manage context — a real problem; context windows are finite. But a standalone summarization stage is a hard-coded, context-blind rule about what survives between steps. It will compress away the one log line that mattered, because at compression time it can't know the investigation was about to need it. You took a decision that depends on everything the agent has seen and froze it into a component that sees almost nothing.
The fixed sequence is a mistake. "DB specialist, then metrics, then logs, then summarize, then write" is a plan committed before a single piece of evidence is in. Real investigations branch on what they find — a log points at a service, the service points at a deploy, the deploy sends you back to metrics. A pipeline can't loop back. You hardened your guess about the order of investigation into the topology of the system, where the model can't override it even when it's obviously right to.
Every one of these felt like good engineering. Each is the same underlying error: a cognitive decision — what to look at, what to keep, what to do next — smuggled into the architecture as a component boundary. In software those boundaries buy you isolation. Here they buy you a permanent ceiling at the level of your own foresight, which is precisely the asset the agent was supposed to exceed.
What actually scales
The agent-native version of that diagram is almost embarrassingly flat:

The complexity doesn't go away. It moves. Instead of pouring your effort into the control-flow graph between components, you pour it into the data interface between the agent and the world — and you let the model own the decisions you were about to hardcode. The patterns that hold up are the ones that scale with more data and more compute instead of with more of your opinions:
- General-purpose sub-agents. When a task needs to be broken up, let the agent break it up and spawn a sub-agent with a fresh context window, rather than you pre-defining "the metrics specialist." This is decomposition driven by the model's read of the actual problem, and it doubles as the cleanest context-management tool you have — the sub-agent does the heavy reading and hands back a tight result. It's a well-documented pattern now, and it's the opposite of a router: the split happens at runtime, by intelligence, not at design time, by you.
- Tool search. Don't curate the ten tools you think this agent needs. Give it a large catalog and let it search for the tool at runtime. This is the bitter lesson in its purest agent form: capability scales with the size of the data/tool corpus, not with the cleverness of your pre-selection. More tools makes it better, not more confused.
- Skills. When you genuinely have reusable procedure — this is how you investigate an OOM, this is the runbook for a cert expiry — encode it as a skill the agent loads on demand, not as a hardwired branch in a router. Skills are how you get the benefits people reach for routers and sequential pipelines to get — specialization, repeatable procedure — without freezing the control flow. The agent decides when a skill applies; you just make good skills available, and you add more over time.
Notice the through-line. Every one of these gets better the more you feed it — more sub-agents, more tools, more skills, more context — and none of them require you to predict the problem in advance. That's what "scales with data" means for an agent harness.
The moral
When you're building an agent harness and you're not sure whether to reach for an AI principle or a software principle, you are in the genuinely new part of this discipline, and your training will betray you. Most of us were software engineers first. Our reflexes were trained on a system that gets better by adding structure, and those reflexes fire hardest exactly when an agent is misbehaving — which is exactly when applying them does the most damage.
The wiring is software; build it like software. But the part that decides what to look at, what to remember, and what to do next is AI, and it gets better the way AI gets better: more general, less opinionated, scaling with data and compute rather than with the cleverness of your decomposition. So for most of the decisions that actually define an agent harness, follow the AI principles — and accept the bitter lesson, even though an agent harness was never a pure AI problem to begin with.
If you're building agentic systems for incident response and want to learn how Traversal can support, book a demo today.