How an AI SRE Supercharges Your SRE Team

An AI SRE is agentic AI for site reliability engineering (SRE): software that investigates live production the way a senior engineer would, forming hypotheses, testing them against real data, and following the causal chain to a root cause. The real question is what it changes about your team's capacity. It takes the mechanical work of an investigation off your engineers and hands it back as leverage: the same team closes incidents faster, handles more of them, and spends its scarcest hours on the work only people can do.
And that is the whole point: an SRE team's scarcest resource isn't headcount. It's the attention of the handful of senior engineers who actually understand how production fits together, and who get pulled into every serious incident because nobody else can move as fast. An AI SRE is leverage on exactly that constraint. It absorbs the manual, rote work of an investigation and hands those engineers an answer, instead of a blank dashboard.
Here is what that looks like in practice, across the work an SRE team actually does. See Traversal’s AI SRE in action today.
It carries the first thirty minutes of every incident
The opening stretch of an incident is mostly manual labor. Someone gets paged, opens five dashboards, scans logs, checks what deployed recently, and starts building a mental timeline. Nothing about this requires senior judgment. It requires speed and stamina, and it burns both at the worst possible time.
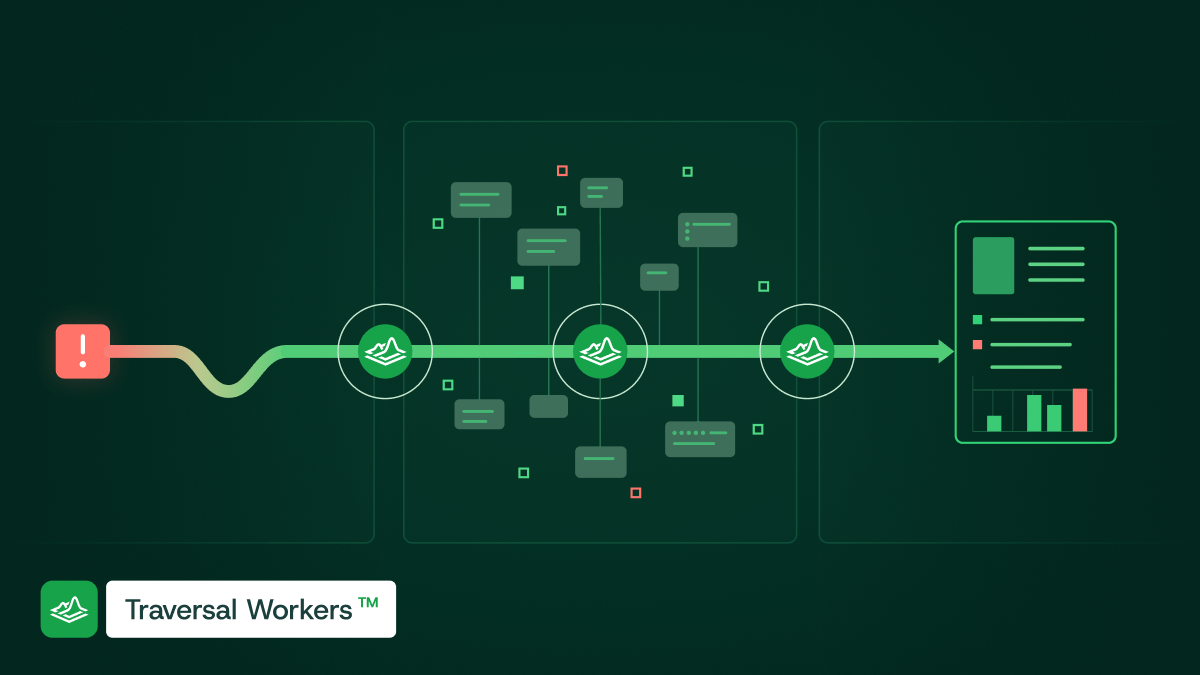
An AI SRE does this the moment an alert fires. It analyzes MELT and recent changes in parallel, maps the dependencies involved, and narrows a wide-open problem to a short list of likely causes before the responder has finished reading the page. By the time a human engages, the question has shifted from "what is going on" to "here is the likely root cause and the evidence for it." That is a fundamentally better place to start.
This is AI for incident response in its most concrete form. The AI SRE is doing the legwork that used to eat the first hour.
It makes causal reasoning available to the whole team, not just the veterans
The reason serious incidents converge on the same two or three people is that root cause analysis across a large system is genuinely hard. It means holding the whole architecture in your head, knowing which relationships are causal versus correlation based, and chasing a symptom back through ten hops of dependencies to the change that actually caused it. Most engineers can't do that yet. The ones who can become a bottleneck.
An AI SRE built on causal reasoning changes who can do that work. When a mid-level engineer can ask production a direct question and get an answer grounded in the actual causal chain, rather than a wall of correlated alerts they have to interpret, they can run an incident that would previously have required waking a principal. The senior engineers still own the hard calls. They just aren't the only ones who can make progress, and they aren't paged for every SEV-2 by default.
The distinction that matters here is causation, not correlation. Traditional tooling surfaces what changed at the same time as the symptom and leaves a human to work out which change actually mattered. An AI SRE that reasons causally does that discrimination itself, which is what makes its output safe to hand to someone who isn't a veteran.
It democratizes production knowledge
A large share of what senior SREs do all day isn't incident response. It's answering questions. How does this service actually behave under load. What depends on the payments API. What will this deploy touch. Which of these alerts have we seen before. Each question is a small interruption, and collectively they are a real tax on the people you least want interrupted.
Once an AI SRE has an accurate, live model of production, those questions have somewhere else to go. At a leading crypto exchange running Traversal, engineers asked the system more questions exploring how production behaves than triaging live incidents, and the single largest category was open-ended exploration: people asking how the system works when nothing was on fire. A new hire can learn the environment in their first week by asking it directly. An engineer planning a change can run a blast-radius check before shipping. None of it requires borrowing a principal's afternoon.
It closes the loop
The work doesn't stop when an incident is over, and neither does the part your team tends to skip. Postmortems get written late, or thinly, or not at all, because the people who could write them well are already onto the next fire.
An AI SRE that stayed in sync with the whole incident can draft the postmortem the moment it ends: a timeline, the root cause analysis, and concrete suggestions for preventing a recurrence, right there for your team to review and sharpen rather than assemble from scratch. The prevention work that usually falls off the end of the process becomes the default instead of the exception. Over time, that's how a team stops fighting the same class of incident twice.
The future is self-driving production
Step back and the pattern is clear. An AI SRE takes over the parts of reliability work that are mechanical, repetitive, or bottlenecked on a few people, and leaves the judgment where it belongs. The direction this points is self-driving production: software that increasingly detects, diagnoses, and helps remediate its own incidents.
Self-driving production is where this is going. Supercharging the team you already have is how it starts: the team gets faster and less fried, while senior engineers get their attention back.
An AI SRE makes the team you have operate like one several times its size, and it makes your best engineers engineers again.
FAQ
It starts investigating the moment an alert fires, reading across logs, metrics, traces, and recent changes in parallel to narrow the problem to a likely root cause before a human has finished reading the page. That means responders begin from evidence and a hypothesis rather than a blank dashboard, which is where most of an incident's time is lost.
Traditional tooling surfaces correlated signals and leaves a human to work out which one actually caused the incident. An AI SRE reasons causally, following the dependency chain from symptom to cause, so its output is an answer rather than a pile of alerts to interpret. Causation, not correlation, is the difference that makes its findings trustworthy.
Self-driving production is the end state: software that detects, diagnoses, and remediates its own incidents. An AI SRE is how teams get there incrementally, by taking over mechanical reliability work first, earning trust, and expanding scope over time, rather than handing production to an autonomous system all at once.

Why Incidents Take So Long to Remediate
.png)